AI & SystemsJanuary 26, 20268 min read
Multi-Agent Orchestration Patterns: Building Production Systems in 2026
Beyond simple agent comparisons. Deep dive into orchestration patterns, handoff strategies, state management, and observability for production multi-agent systems.
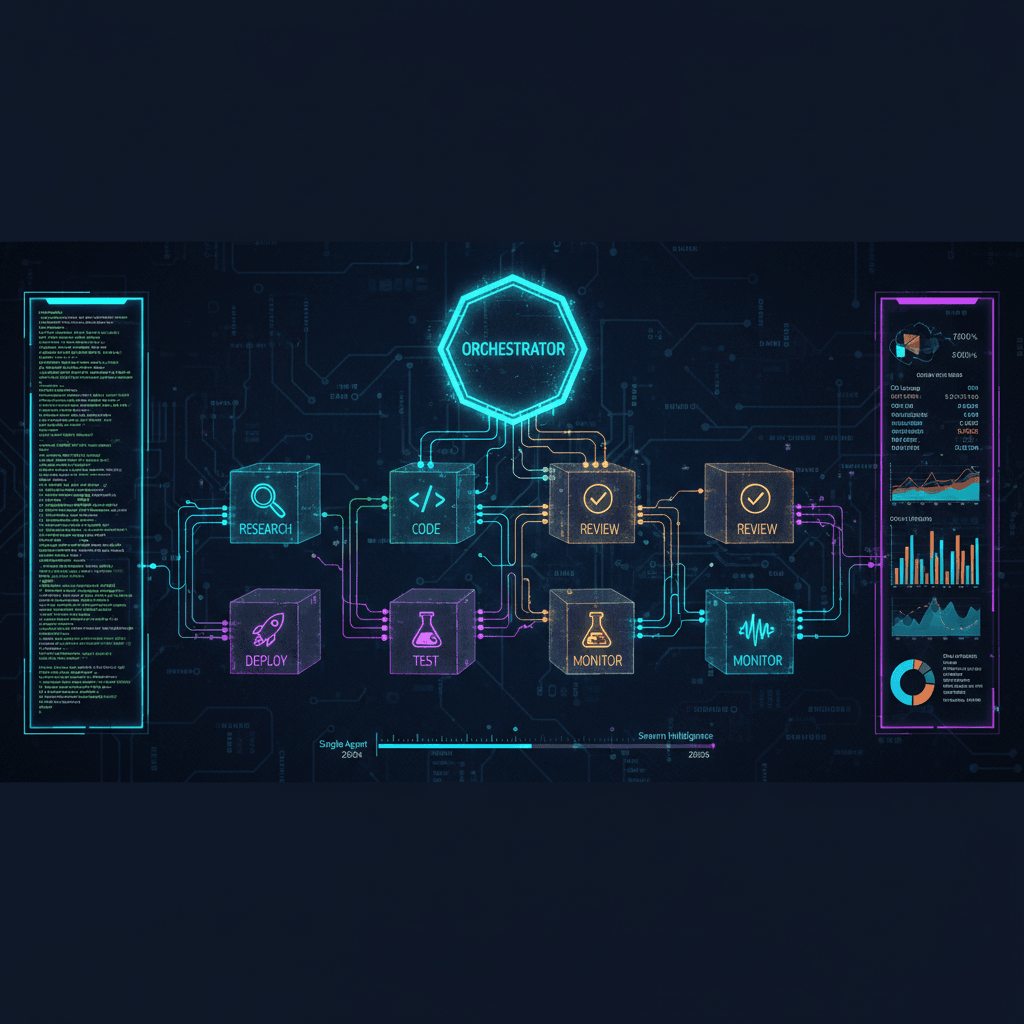
Picture this: You're orchestrating a track with four producers in different cities. Each has their specialty—drums, melody, bass, vocals. The magic isn't in any single element. It's in how they hand off to each other, when they sync, how they recover when someone drops the beat.
Multi-agent AI systems work exactly the same way.
TL;DR: 72% of enterprise AI projects now use multi-agent architectures. This guide covers the orchestration patterns that make them work: handoff strategies, state management approaches, error handling, and observability. Not framework comparisons—system design.
Why Orchestration Matters More Than Framework Choice
The framework debates (LangGraph vs CrewAI vs AutoGen) miss the point. The hard problems are:
- How do agents hand off work? (not which framework to use)
- How do you manage state across agents? (not which LLM is best)
- How do you handle failures gracefully? (not which tool is fastest)
- How do you observe what's happening? (not which UI is prettiest)
These patterns work across frameworks. Master them, and you can implement in any stack.
Pattern 1: The Handoff Strategies
Sequential Handoff (Pipeline)
The simplest pattern. Agent A completes, passes output to Agent B.
[Research Agent] → [Analysis Agent] → [Writing Agent] → [Review Agent]
When to use:
- Linear workflows with clear stages
- Each stage has different expertise requirements
- Output of one stage is input to next
Implementation considerations:
- Define clear contracts between agents (what format? what fields?)
- Handle partial failures (what if Analysis fails but Research succeeded?)
- Consider checkpointing (can you resume from middle?)
Parallel Handoff (Fan-Out/Fan-In)
Multiple agents work simultaneously, results merge.

When to use:
- Independent subtasks that don't depend on each other
- Time-sensitive operations where parallelism matters
- Diverse expertise needed simultaneously
Implementation considerations:
- Define merge strategy (how do you combine results?)
- Handle stragglers (wait for all? timeout?)
- Manage token budgets across parallel branches
Hierarchical Handoff (Delegation)
Manager agent delegates to specialists, aggregates results.

When to use:
- Complex problems requiring decomposition
- When you need a "thinking" layer above execution
- Dynamic task allocation based on problem analysis
Implementation considerations:
- Manager needs strong reasoning (use capable model)
- Define delegation protocol (how does manager assign?)
- Handle re-delegation (what if specialist can't complete?)
Iterative Handoff (Loop)
Agents pass work back and forth until quality threshold met.

When to use:
- Quality-sensitive outputs
- Creative generation with refinement
- Code generation with testing
Implementation considerations:
- Define termination criteria (how many iterations max?)
- Prevent infinite loops (score trending wrong direction?)
- Balance quality vs cost (each iteration costs tokens)
Pattern 2: State Management Approaches
Shared State (Blackboard Pattern)
All agents read/write to a central state object.
# Conceptual - works across frameworks
class SharedState:
context: dict # Shared context
messages: list # Conversation history
artifacts: dict # Generated outputs
metadata: dict # Tracking info
# Each agent reads and writes
def research_agent(state: SharedState) -> SharedState:
# Read existing context
topic = state.context.get("topic")
# Do work
findings = research(topic)
# Write results
state.artifacts["research"] = findings
return state
Pros:
- Simple mental model
- Easy debugging (inspect state at any point)
- Natural for graph-based frameworks (LangGraph)
Cons:
- Potential for conflicts (two agents write same key)
- State can grow large (context window concerns)
- Harder to parallelize (locking?)
Message Passing (Actor Pattern)
Agents communicate through messages, maintain local state.
# Conceptual actor model
class ResearchActor:
def __init__(self):
self.local_cache = {}
def handle_message(self, msg: Message) -> Message:
if msg.type == "research_request":
findings = self.research(msg.topic)
return Message(type="research_complete", data=findings)
Pros:
- Natural isolation (each agent is independent)
- Scales well (no shared state bottleneck)
- Maps to distributed systems patterns
Cons:
- More complex coordination
- Message format design is critical
- Harder to inspect "global" state
Event Sourcing (Append-Only Log)
All state changes are events. Current state = replay of events.
# Event log
events = [
{"type": "task_created", "data": {...}, "timestamp": ...},
{"type": "research_started", "agent": "research_01", ...},
{"type": "research_completed", "findings": [...], ...},
{"type": "analysis_started", "agent": "analysis_01", ...},
# ...
]
# Current state = fold over events
def get_current_state(events):
state = initial_state()
for event in events:
state = apply_event(state, event)
return state
Pros:
- Complete audit trail
- Time-travel debugging
- Natural for compliance requirements
Cons:
- More complex implementation
- Storage growth over time
- Replay can be slow for long histories
Pattern 3: Error Handling Strategies
Retry with Backoff
Simple but effective for transient failures.
async def call_agent_with_retry(agent, input, max_retries=3):
for attempt in range(max_retries):
try:
return await agent.run(input)
except TransientError:
wait_time = 2 ** attempt # Exponential backoff
await asyncio.sleep(wait_time)
raise MaxRetriesExceeded()
Fallback Chain
Try primary, fall back to alternatives.
async def call_with_fallback(input):
agents = [primary_agent, secondary_agent, simple_fallback]
for agent in agents:
try:
return await agent.run(input)
except AgentError as e:
log.warning(f"{agent.name} failed: {e}")
continue
raise AllAgentsFailed()
Circuit Breaker
Prevent cascade failures by failing fast.
class CircuitBreaker:
def __init__(self, failure_threshold=5, reset_timeout=60):
self.failures = 0
self.state = "closed" # closed, open, half-open
self.last_failure_time = None
async def call(self, agent, input):
if self.state == "open":
if time.time() - self.last_failure_time > self.reset_timeout:
self.state = "half-open"
else:
raise CircuitOpen()
try:
result = await agent.run(input)
self.failures = 0
self.state = "closed"
return result
except Exception:
self.failures += 1
self.last_failure_time = time.time()
if self.failures >= self.failure_threshold:
self.state = "open"
raise
Human-in-the-Loop Escalation
When agents can't handle it, route to humans.
async def process_with_escalation(task):
try:
# Try automated processing
result = await agent_pipeline.run(task)
# Confidence check
if result.confidence < CONFIDENCE_THRESHOLD:
return await escalate_to_human(task, result)
return result
except CriticalDecisionRequired:
return await escalate_to_human(task, context="requires_approval")
Pattern 4: Observability Stack
Structured Logging
Every agent action should be traceable.
@traced
async def research_agent(state):
with span("research_agent") as s:
s.set_attribute("topic", state.context["topic"])
s.set_attribute("model", "claude-3-opus")
result = await llm.generate(...)
s.set_attribute("tokens_used", result.usage.total_tokens)
s.set_attribute("latency_ms", result.latency)
return result
Metrics to Track
| Metric | Why It Matters |
|---|---|
| Latency per agent | Identify bottlenecks |
| Token usage per agent | Cost attribution |
| Success/failure rates | Reliability tracking |
| Handoff counts | Flow analysis |
| Human escalation rate | Automation effectiveness |
| Quality scores | Output monitoring |
Trace Visualization

Alerting Rules
alerts:
- name: high_failure_rate
condition: agent_failures / agent_calls > 0.1
window: 5m
action: page_oncall
- name: cost_spike
condition: hourly_token_cost > 2x average
action: notify_slack
- name: latency_degradation
condition: p95_latency > 30s
action: notify_slack
Putting It Together: A Reference Architecture

Frequently Asked Questions
How many agents should a system have?
Start with the minimum needed. Each agent adds complexity. A well-designed 3-agent system beats a poorly-designed 10-agent system. Scale up when you have evidence of need.
Should I use one framework or mix them?
Use one primary framework for orchestration. Mix only when you have specific needs (e.g., LangGraph for orchestration, CrewAI agents for specific tasks). Complexity is the enemy.
How do I debug multi-agent failures?
Structured logging + trace visualization. You need to see the full flow to diagnose issues. Invest in observability before you need it.
What's the biggest mistake teams make?
Starting with complex architectures before validating the use case. Build the simplest thing that could work, measure, then add complexity.
How do I handle agent disagreements?
Define arbitration rules upfront. Options: majority vote, confidence weighting, hierarchical override, human escalation. Pick one and be consistent.
Key Takeaways
- Orchestration patterns are framework-agnostic - Master the patterns, implement in any stack
- Handoff strategy determines system behavior - Choose based on your workflow shape
- State management is critical - Shared state vs message passing vs event sourcing
- Error handling prevents cascades - Retry, fallback, circuit breaker, escalation
- Observability is not optional - You can't fix what you can't see
The 72% of enterprise projects using multi-agent systems didn't get there by choosing the right framework. They got there by understanding orchestration patterns.
Building multi-agent systems? Check the AI Architecture Hub for blueprints, BYOK prototypes, and deployment templates.
Sources:
- LangGraph Documentation
- CrewAI Documentation
- Microsoft AutoGen
- OpenTelemetry for LLMs
- G2 Enterprise AI Agents Report 2026
Related Articles
- Production LLM Agents on OCI — Enterprise deployment architecture
- Swarm Intelligence for Multi-Agent Systems — Advanced coordination patterns
- What is Agentic AI? — Understanding autonomous AI agents
- Agent Family Architecture vs Agent Swarms — The architectural choice that determines whether multi-agent stacks scale coherently or fragment under load
- No Bad Parts: Sovereign AI — The IFS-derived governance pattern these orchestration patterns are converging toward
- Self-Led AI Architecture (research) — Internal governance over agent swarms
Get Started
Build your first AI system
Step-by-step guide to setting up ACOS, creating your first agent, and shipping real products with AI.
Start buildingTemplates & Blueprints
Production-ready architecture
Download AI architecture templates, multi-agent blueprints, and prompt engineering patterns.
Browse templatesInner Circle
Join the builder community
Connect with creators and architects shipping AI products. Weekly office hours, shared resources, direct access.
Join the circleRelated Research
Read on FrankX.AI — AI Architecture, Music & Creator Intelligence
Stay in the intelligence loop
Weekly field notes on AI systems, production patterns, and builder strategy.
Continue Reading

Enterprise AI6 min read
The Enterprise Agent Roadmap 2026: Multi-Agent Orchestration Patterns
Your vertical hierarchy is too slow for multi-agent systems. The Fractal Triad topology with LangGraph, CrewAI, and MCP integration for enterprise orchestration.
Read article
AI & Systems9 min read
Oracle GenAI Agents vs LangGraph vs CrewAI: Enterprise AI Agent Comparison 2026
A practical comparison of OCI GenAI Agents, LangGraph, and CrewAI for enterprise deployments. Features, pricing, and decision framework from an AI architect's perspective.
Read article
Enterprise AI22 min read
Production LLMs & AI Agents on OCI: Part 2 - Six Agent Orchestration Patterns
The complete pattern library for agent orchestration on OCI: Sequential, Concurrent, Group Chat, Handoff, Orchestrator-Worker, and Human-in-the-Loop. Decision criteria, OCI service mapping, and when to use each pattern.
Read article