Intelligence DispatchesMarch 16, 202615 min read
AI Architecture Patterns for Solo Builders
The system design decisions that matter when one person builds what teams used to require — from monolith to agents.
🎯
Reading Goal
You will know the architectural patterns that let one person build and maintain what previously required a team — with AI as the force multiplier.
TL;DR: Solo builders face a unique architectural challenge: every system you build, you also maintain. The patterns that work for teams — microservices, complex CI/CD, multi-repo orchestration — create maintenance debt that one person cannot service. The patterns that work: monolith-first with AI agents for specialized tasks, file-based content (MDX over CMS), MCP for integration, and n8n for automation. I ship a 170+ page site, 9 automation workflows, and a full product catalog as one person. Here is the architecture that makes it possible.
There is an architectural trap that catches almost every solo builder who discovers AI tools: you start with a simple problem, solve it elegantly, then keep adding systems until the maintenance burden exceeds your capacity to ship.
I have been in that trap. I have also built my way out of it.
The frankx.ai stack — Next.js monolith, MDX content, Vercel deployment, n8n automation, ACOS as the operating system, MCP as the integration layer — runs at a scale that would have required a three to five person team two years ago. One person designs it, builds it, ships it, and keeps it running. This article is about the architectural decisions that made that possible, and the ones that would have sunk it.
The Solo Builder's Constraint Is Not Skill — It Is Maintenance Surface
Before getting into specific patterns, the framing matters. The question most solo builders ask is: "How do I build this fast?" The question that actually determines your success is: "How will I maintain this in six months when I am working on something else?"
Every technical decision you make today creates a maintenance contract with your future self. Microservices require you to maintain service boundaries, inter-service communication, independent deployment pipelines, and distributed debugging. A content management system requires a running database, authentication, API contracts, and migration scripts. Custom CI/CD requires pipeline maintenance, secret management, and integration upkeep.
These are not bad choices in isolation. On a team, the maintenance surface is distributed across specialists. Solo, you own all of it.
The architectural principle that follows from this: minimize maintenance surface per unit of capability. Every component you add must justify itself not just by what it enables but by what it costs to keep running.
I call this the complexity budget. You have a fixed cognitive and time budget for maintenance. Every system you add draws from it. When the budget is exhausted, your ability to ship new things collapses — you spend all your time keeping existing things working.
The goal of good solo architecture is to maximize capability within a sustainable complexity budget.
Pattern 1: Monolith-First, Always
The microservices movement gave us a powerful pattern for teams. It also gave solo builders a cargo cult that reliably produces unmaintainable systems.
The argument for microservices is real: independent scaling, technology flexibility, team autonomy, blast radius isolation. These benefits matter enormously when you have multiple teams stepping on each other's work. Solo, most of these benefits do not apply — and you pay all the costs.
What goes wrong with solo microservices:
You separate your frontend, backend API, auth service, and notification service into four repositories with four deployment pipelines. For six weeks it feels clean. Then a contract changes between the API and the frontend. Now you are coordinating a deployment across two repos, debugging network calls between services, and maintaining version compatibility. This is exactly the problem microservices were designed to solve at team scale — but you are one person, and the problem was never team coordination. It was complexity management. Microservices made that worse.
What works: the Next.js App Router monolith.
The frankx.ai codebase is a single Next.js application. API routes live in app/api/. Page components live in app/. Shared utilities live in lib/. The entire thing deploys as a single Vercel project with one git push.
This is not a compromise — it is the right architecture for this scale. TypeScript gives you compile-time contract enforcement across the entire codebase without inter-service coordination. Server components and API routes in the same repo means refactoring a data model updates both the API and the display layer in a single commit. One deployment pipeline means one thing to debug when something breaks.
The monolith is not the architecture you scale away from. It is the architecture you start with and evolve carefully when you have specific, demonstrated scaling problems that justify the added complexity.
Pattern 2: File-Based Content Over CMS
The instinct to reach for a headless CMS is understandable. Contentful, Sanity, and Prismic provide nice editing interfaces, content modeling tools, and API endpoints. They also introduce: a running external service dependency, API rate limits, authentication overhead, content migration complexity, and monthly costs that grow with usage.
For solo builders shipping content-heavy sites, MDX in the repository is a superior architecture across almost every dimension that matters.
MDX files are versioned with your code. The same pull request that adds a new feature can update the relevant documentation. No CMS API to call at build time means one fewer failure surface. Content lives in the same mental model as everything else — it is just files. When you need to update 50 blog posts with a new frontmatter field, you write a script. No API rate limits, no migration UI.
The frankx.ai blog runs entirely on MDX files in content/blog/. The build pipeline reads the files, processes the frontmatter, and generates static pages. The entire content system has zero external dependencies.
Where file-based content falls short: highly collaborative editorial workflows where non-technical editors need a visual interface. If you are a solo builder or a small team where everyone is comfortable with text editors and Git, this limitation does not apply.
The compound benefit: because content is in the repository, Claude Code can read, generate, and edit blog posts in the same workflow as everything else. An AI writing tool that integrates with a CMS requires custom tooling. An AI that can read and write files integrates with MDX for free.
Pattern 3: MCP Over Custom API Integrations
The traditional approach to integrating third-party services is to write custom API integration code: fetch wrappers, auth handling, rate limiting, error handling, type definitions. For one integration, this is manageable. For ten integrations across multiple services, it is a significant maintenance burden — every API that changes their contract breaks your integration code.
Model Context Protocol changes this calculation entirely.
MCP provides a standard interface for AI models to interact with external systems. Instead of writing custom integration code for each service, you install an MCP server and the AI model handles the integration. The frankx.ai development environment runs MCP servers for Vercel, Notion, Slack, Linear, Figma, and n8n — all without a single line of custom integration code.
The implications for solo builders:
You get integrations at a fraction of the development cost. A Vercel MCP server means Claude Code can check deployment status, read build logs, and inspect runtime logs without you building any of that tooling. The MCP ecosystem is growing rapidly — if a service you need has an MCP server, your integration maintenance cost drops close to zero.
The architectural pattern that follows: before writing any API integration code, check whether an MCP server exists for that service. If it does, your integration is an installation command, not a development project.
Where custom API code still makes sense: when you have a very specific integration requirement that no existing MCP server handles, or when the integration needs to run in production outside of an AI session context. MCP servers are session-bound — they run during your development or AI assistant sessions, not as persistent production services.
For persistent production integrations, the right tool is n8n.
Pattern 4: n8n Over Custom Automation Backends
Every solo builder eventually needs automation: "when X happens, do Y." Send an email when someone purchases a product. Sync content between systems when a new post is published. Run a daily report and send it to Slack. Generate newsletter content from blog articles.
The instinct is to write these as custom backend code: Node.js scripts, Lambda functions, cron jobs. This works until you have fifteen of them with different triggers, different failure modes, and different debugging requirements.
n8n as the automation layer changes this. Nine active automation workflows power the frankx.ai backend: the morning intelligence brief, the content atomizer that turns blog posts into social media threads, the music catalog sync, the newsletter engine, the n8n automation empire that routes between all of them. None of this required writing custom backend code.
The maintenance properties are different in kind, not just degree. When an n8n workflow fails, the error is visible in the execution log with the specific node that failed and the error message. Debugging a custom cron job that silently fails requires log archaeology. Changing a workflow step means dragging a node — not editing code, committing, deploying, and testing.
For solo builders, the specific advantages of n8n over custom automation code:
Visual execution history. Every workflow run is logged with inputs, outputs, and timing at each step. When something breaks at 3am, you have a complete audit trail.
Webhook triggers without infrastructure. n8n provides webhook URLs that any service can call. No API Gateway, no Lambda, no infrastructure to manage.
Credential management. OAuth flows, API keys, and service credentials are managed in n8n's credential store. No secrets scattered across environment variables in fifteen places.
AI integration is native. n8n's AI nodes connect to any LLM via API. The content atomizer workflow calls Gemini Flash to transform blog posts — no custom code, just a configured AI node in the workflow graph.
The trade-off: n8n is a service you need to run. I use Railway for the deployment, which removes the infrastructure burden. The cost is approximately $8-15/month for the compute. That cost is justified by eliminating the development and maintenance time for equivalent custom automation code.
How AI Changes the Equation: Claude Code as a Team Member
The patterns above — monolith, file-based content, MCP integration, n8n automation — describe the application architecture. The AI layer operates on top of this and changes what one person can accomplish within it.
Claude Code, configured through the ACOS system, functions as a technical collaborator that shares context about the entire codebase. It knows the architecture decisions, the component patterns, the content schema, the deployment workflow. When I add a new feature, Claude Code handles the implementation work at team-member pace. I provide direction and review; it provides execution.
This is not automation replacing judgment. It is leverage that multiplies the output of good judgment. The architectural decisions I make still determine whether the system is maintainable. But the implementation time per decision collapses dramatically.
The practical consequence: the bottleneck shifts from implementation speed to decision quality. A solo builder with well-configured AI assistance can ship at team velocity. But only if the underlying architecture has a low enough complexity surface that the AI assistant can reason about it correctly. A tangle of microservices, external dependencies, and custom integration code creates a context problem for AI assistance that mirrors the maintenance problem it creates for you.
Simple, coherent architecture is doubly valuable when AI assistance is in the picture: it is easier for you to maintain and easier for an AI to reason about correctly.
The frankx.ai Stack as a Case Study
Here is the complete production stack, with the reasoning behind each choice:
Next.js App Router — monolith, single deployment, TypeScript throughout, server and client components in the same mental model. Zero inter-service coordination.
MDX content — versioned with code, no external dependencies, full AI assistance for generation and editing. 170+ pages and growing with no CMS subscription.
Vercel — managed deployment, edge CDN, serverless functions, analytics, and preview deployments included. Eliminated: server management, CDN configuration, deployment pipeline maintenance.
Vercel Blob — product file storage. PDFs, audio files. No S3 configuration, no IAM policies. One API, one billing line item.
Resend — transactional email. Product delivery, welcome sequences, lead nurture. API-first, simple pricing, no SMTP configuration.
n8n on Railway — nine automation workflows. The intelligence brief, content atomizer, music sync, newsletter engine. No custom backend code.
ACOS — the operating system layer. Skills, agents, memory, hooks — the configuration that turns Claude Code into a specialized technical collaborator for this specific stack.
MCP servers — Vercel, Notion, Slack, Linear, Figma, n8n. Zero custom integration code.
The entire infrastructure bill runs under $80/month. The capability this enables is comparable to what a three to five person team would have managed two years ago.
The Patterns That Break Solo
For completeness, the architectural choices that look professional but consistently create unmanageable maintenance debt for solo builders:
Separate database clusters per service. If you have PostgreSQL for user data, Redis for caching, and MongoDB for content in three separately managed instances, you own three operational concerns. Vercel Postgres or a managed single-database solution costs slightly more per unit but eliminates two-thirds of your operational surface.
Custom authentication from scratch. NextAuth, Clerk, and Auth0 exist. Every hour you spend building custom JWT rotation, session management, and OAuth flows is an hour not spent on the problems that differentiate your product.
Multi-repo coordination. The frankx.ai system uses two repos: the private development workspace and the production Vercel repo. That is already pushing the limit for solo management. Every additional repo is an additional surface for merge conflicts, dependency drift, and deployment coordination.
Custom CI/CD pipelines. Vercel's built-in deployment covers 95% of what most Next.js projects need. Custom GitHub Actions pipelines for parallel test runs, deployment gates, and staging environments look impressive and consume disproportionate maintenance energy.
The pattern: anything that requires ongoing human intervention to keep running is a liability, not an asset. Choose managed services, standard protocols, and well-maintained open source tools over custom-built alternatives whenever the capability is equivalent.
Building Your Complexity Budget
Here is a practical framework for evaluating architectural decisions before you make them:
Ask: what breaks if this component goes down? If the answer is "everything," the component is a critical dependency and needs either high reliability guarantees (managed service) or simple replaceability (stateless, easy to restart).
Ask: how long to debug a failure at 2am? Some systems make failure obvious: a Vercel deployment shows exactly which build step failed with the full log. Others require archaeology. Your architecture should skew toward the former.
Ask: what happens in six months when I have moved on to the next thing? Automation and systems you build today will need to keep running when your attention is elsewhere. Complexity that requires active stewardship is a time bomb.
Ask: can Claude Code reason about this correctly? If the architecture is too tangled for AI assistance to navigate reliably, it is probably too tangled for you to maintain efficiently.
The ACOS framework operationalizes these questions into a practical operating system for AI-assisted solo building. See also how I run 9 automation workflows with n8n and the Personal AI CoE research hub for the enterprise framework that underlies this architecture.
For the specific Claude Code configuration that ties this together, read how to write a CLAUDE.md that works.
Frequently Asked Questions
When should a solo builder consider adding a second service or database?
When a specific, demonstrated scaling constraint exists that cannot be addressed within the monolith without compromising the core application's reliability or performance. Not when you anticipate future scaling needs. Not when the architecture would "look cleaner" as a separate service. The bar is a real problem in production, not a theoretical future problem. Most solo projects never hit this bar.
How does this architecture scale if the project succeeds and I hire a first employee?
Better than you might expect. A clean monolith with clear module boundaries, good TypeScript types, and documented conventions is significantly easier to onboard a new team member into than a distributed microservice system. The migration from monolith to services, when genuinely needed, is a known engineering problem with established patterns. The debt from premature microservices is not.
Is n8n the right automation layer or are there better options?
For solo builders who want visual workflow management, self-hosted control, and strong AI integration, n8n is the best current option in the open-source space. Zapier and Make are good managed alternatives if you prefer not to run your own instance — at higher cost but zero operational overhead. Custom code (Lambda functions, cron jobs) is appropriate when you have very specific requirements that workflow tools do not handle well, but should be a last resort given the maintenance implications.
How do you handle database needs in this architecture?
Vercel Postgres for relational data (user accounts, transactions, structured records), Vercel Blob for file storage (PDFs, images, audio). This covers the majority of data storage needs for content sites and creator platforms without separate infrastructure to manage. For AI-specific use cases that need vector search, adding a single managed vector database (like Supabase with pgvector, or a dedicated Qdrant instance) is a reasonable addition when RAG or semantic search becomes a specific product requirement.
What is the first architectural decision a solo builder should make?
Define your complexity budget explicitly before you start. Write down how many hours per week you can allocate to maintenance (not building — maintaining). Then evaluate every architectural decision against that budget. This makes the trade-offs visible before you commit to them, rather than discovering the maintenance debt after the fact.
The architecture that ships is better than the architecture that scales. Build for where you are, with explicit understanding of what you are trading away. Then ship.
Get Started
Build your first AI system
Step-by-step guide to setting up ACOS, creating your first agent, and shipping real products with AI.
Start buildingTemplates & Blueprints
Production-ready architecture
Download AI architecture templates, multi-agent blueprints, and prompt engineering patterns.
Browse templatesInner Circle
Join the builder community
Connect with creators and architects shipping AI products. Weekly office hours, shared resources, direct access.
Join the circleRead on FrankX.AI — AI Architecture, Music & Creator Intelligence
Stay in the intelligence loop
Weekly field notes on AI systems, production patterns, and builder strategy.
Continue Reading

Creator Systems6 min read
How I Configured Claude Code with ACOS and 21 MCP Servers
Step-by-step guide to building a production-grade AI coding environment with ACOS, Claude Code, MCP servers, and custom agent workflows. From zero to shipping.
Read article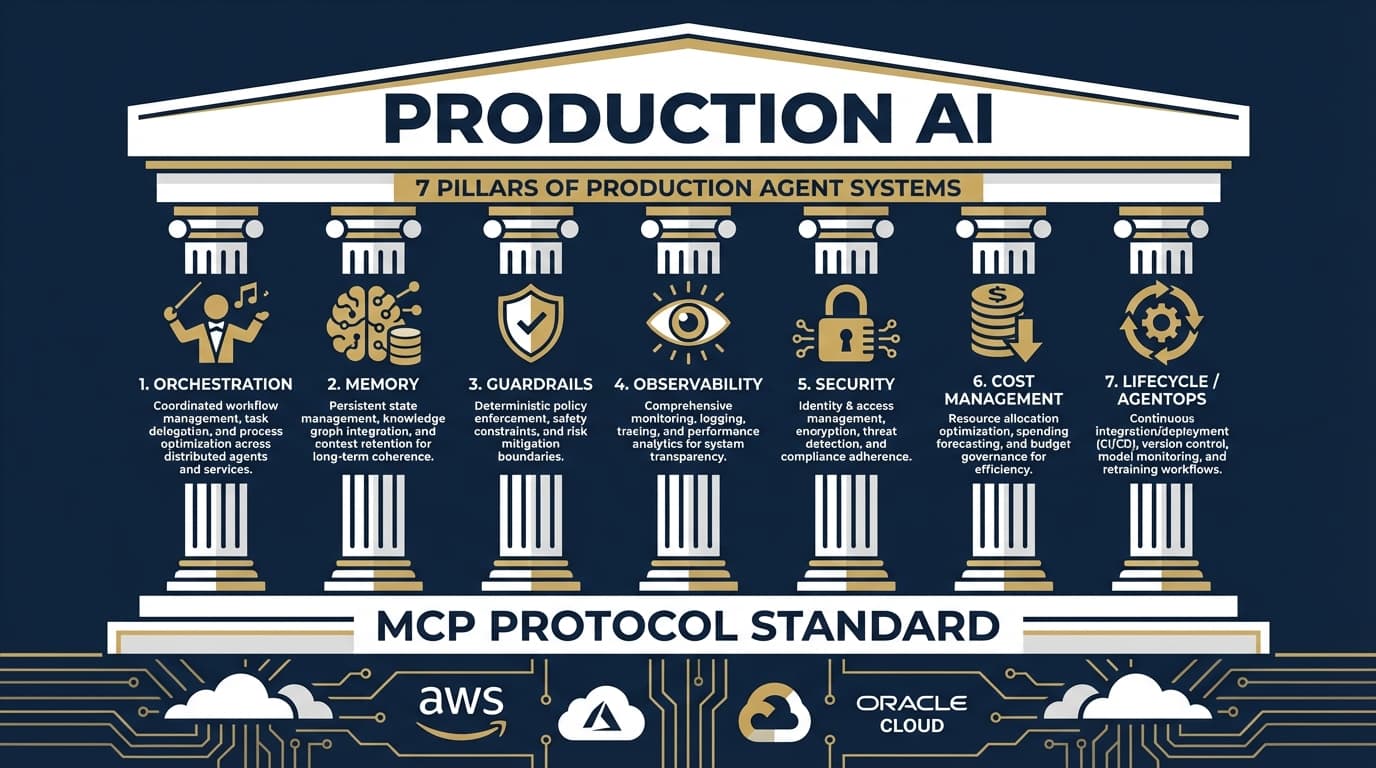
AI Architecture9 min read
The 7 Pillars of Production Agent Systems: What Actually Matters in 2026
2026 marks the shift from AI demos to production deployments. Here's the architectural framework that emerged from analyzing AWS, Azure, Google Cloud, OpenAI, Anthropic, and Oracle's approaches to production-ready AI agents.
Read article
Workshops12 min
Build Your First MCP Server: The Model Context Protocol Workshop
Learn to build production-grade MCP servers that connect AI to your data. Master resources, tools, and prompts with the open standard revolutionizing AI integration.
Read article