Enterprise AIJanuary 21, 202625 min read
Production LLMs & AI Agents on OCI: Part 3 - The Operating Model
The definitive guide to operating production AI systems. 5-stage maturity model, evaluation pipelines, MLOps for GenAI, incident response runbooks, cost optimization, and team operating models.
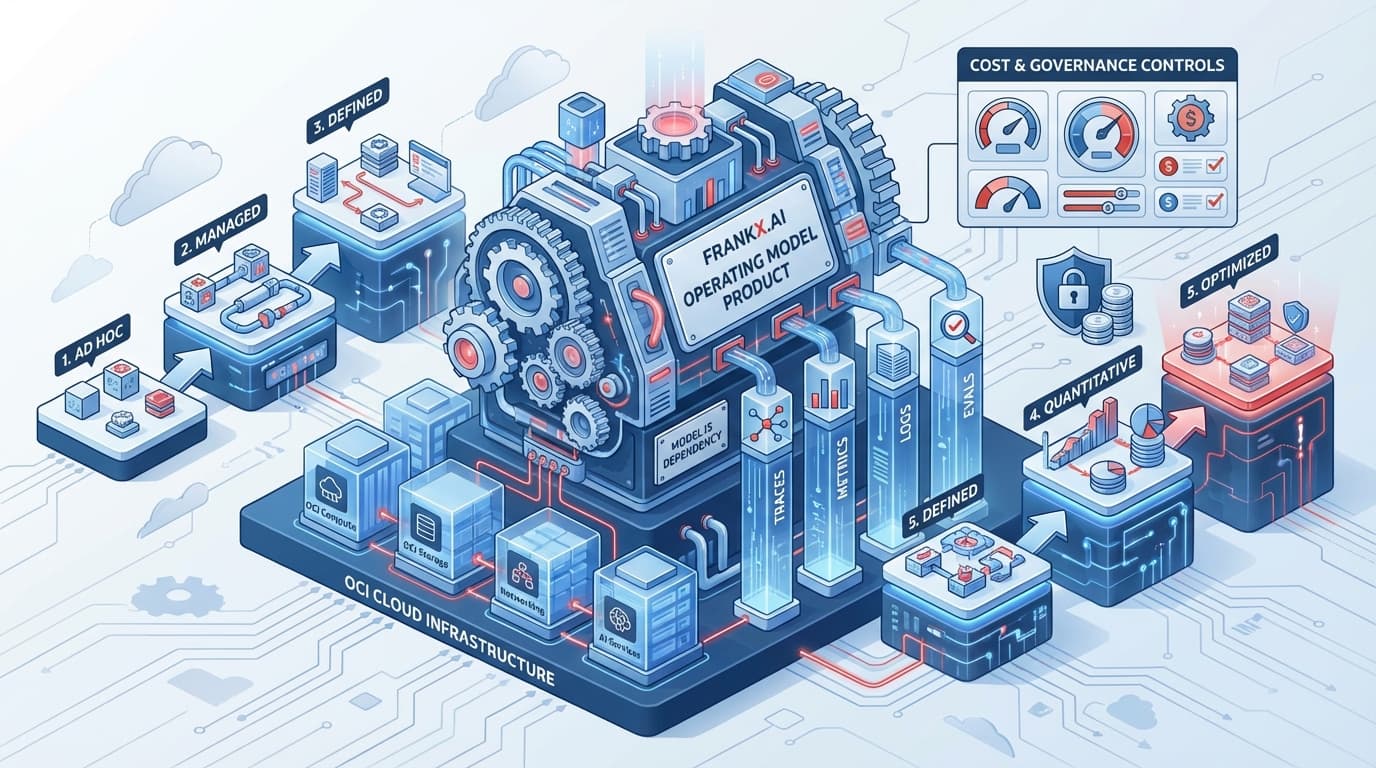
Production LLMs and AI Agents on OCI: The Operating Model
TL;DR: Production GenAI systems fail not because of bad models, but because of missing operating models. This guide provides a complete 5-stage maturity framework, evaluation pipelines, MLOps architecture, incident runbooks, cost optimization strategies, and team operating models—all mapped to OCI services.
The Operating Model Imperative
Most GenAI projects invest 90% effort on models and 10% on operations. Production systems require the inverse: the model is a dependency; the operating model is the product.

An operating model answers these critical questions:
| Question | Why It Matters | Consequence of Not Answering |
|---|---|---|
| How do we version prompt changes? | Reproducibility, rollback capability | Cannot diagnose regressions |
| How do we know if quality is degrading? | Early detection of model drift | Users discover issues before you |
| How do we control costs? | Budget predictability | Surprise bills, service shutdown |
| How do we respond to incidents? | Mean Time To Recovery | Extended outages, reputation damage |
| How do we maintain compliance? | Regulatory requirements | Fines, audit failures |
The 5-Stage AI Operations Maturity Model
Based on production learnings from enterprise deployments and aligned with industry frameworks like Google's ADK maturity guidance.

Maturity Assessment Scorecard
Rate your current state (1-5) for each dimension:
| Dimension | Stage 1 | Stage 2 | Stage 3 | Stage 4 | Stage 5 |
|---|---|---|---|---|---|
| Versioning | None | Git for prompts | Semantic versioning + registry | Automated promotion | ML-selected versions |
| Monitoring | None | Error logs only | Full traces + metrics | Anomaly detection | Predictive alerts |
| Evaluation | Manual testing | Golden sets | Automated in CI/CD | Online A/B tests | Continuous learning |
| Cost Mgmt | None | Bill review | Per-request tracking | Budget enforcement | Dynamic optimization |
| Incident Response | Ad-hoc | Runbooks | Automated detection | Auto-remediation | Predictive prevention |
| Governance | None | Manual review | Policy-as-code | Automated compliance | Continuous audit |
Scoring:
- 6-12: Stage 1 (Ad-hoc)
- 13-18: Stage 2 (Managed)
- 19-24: Stage 3 (Measured)
- 25-28: Stage 4 (Optimized)
- 29-30: Stage 5 (Autonomous)
Stage-by-Stage Implementation Roadmap
Stage 1 → Stage 2: Foundation (Weeks 1-4)

Key Deliverables:
- Prompt repository structure
- OCI Logging enabled
- Basic dashboard with error rates
- 3 incident runbooks
- Golden test set with 50 cases
Stage 2 → Stage 3: Measurement (Weeks 5-12)

Stage 3 → Stage 4: Optimization (Months 4-6)
| Capability | Implementation | OCI Service |
|---|---|---|
| A/B Testing | Traffic splitting for prompt variants | OCI API Gateway + Feature Flags |
| Dynamic Routing | Route to optimal model based on query | OCI Functions + Generative AI |
| Automated Quality Gates | Block deployments below quality threshold | OCI DevOps + Functions |
| Anomaly Detection | ML-based detection of quality degradation | OCI Anomaly Detection |
| Cost Optimization | Automatic model downgrade under budget pressure | OCI Functions + Budgets |
Stage 4 → Stage 5: Autonomy (Month 6+)

Observability Architecture
The Four Pillars of AI Observability

Distributed Trace Structure

SLO Definition Framework
| SLO Category | Metric | Target | Burn Rate Alert | OCI Implementation |
|---|---|---|---|---|
| Availability | Success rate | 99.9% | 1% in 1hr | OCI Monitoring Alarms |
| Latency | P95 response time | < 5s | P95 > 8s | APM Service Level Objectives |
| Quality | Groundedness score | > 90% | < 85% avg | Custom metrics + Functions |
| Cost | Cost per query | < $0.05 | > $0.10 avg | Cost Analysis + Budgets |
| Safety | Harmful output rate | < 0.1% | Any detection | Logging + Content Moderation |
OCI Observability Stack

Evaluation Pipeline Architecture
Offline vs Online Evaluation

Evaluation Metrics Framework
| Category | Metric | Measurement Method | Target | OCI Implementation |
|---|---|---|---|---|
| Semantic | Response relevance | Embedding similarity to expected | > 0.85 | Functions + Generative AI |
| Factual | Groundedness | Citation verification | > 0.90 | Functions + custom |
| Completeness | Coverage | Checklist evaluation | > 0.80 | LLM-as-judge |
| Safety | Harmful content | Classifier detection | < 0.001 | Content Moderation API |
| Latency | Response time | P95 measurement | < 5s | APM |
| Cost | Per-request cost | Token tracking | < $0.05 | Custom metrics |
Golden Set Design

CI/CD Integration

Prompt & Agent Lifecycle Management
Prompts as Code

Deployment Strategies

Deployment Decision Framework
| Factor | Blue/Green | Canary | Shadow |
|---|---|---|---|
| Risk tolerance | Low | Very low | None |
| Rollback time | Instant | Fast | N/A |
| Resource cost | 2x during deploy | 1.05x | 2x always |
| Comparison data | Before/after | Statistical | Side-by-side |
| User impact on failure | None (if quick) | Minimal (5%) | None |
| Best use case | Breaking changes | Optimizations | Model swaps |
Cost Management Architecture
Cost Attribution Model

Cost Components Breakdown
| Component | Typical Share | Optimization Strategy | OCI Control |
|---|---|---|---|
| LLM Inference | 40-60% | Prompt optimization, caching, model selection | Generative AI pricing tiers |
| Embedding | 10-20% | Batch processing, caching | Generative AI embed pricing |
| Vector DB | 10-15% | Index optimization, partitioning | Autonomous DB tiers |
| Compute | 10-20% | Right-sizing, autoscaling | OKE node pools, Functions |
| Storage | 5-10% | Tiering, lifecycle policies | Object Storage tiers |
| Network | 5-10% | Regional deployment | VCN optimization |
Cost Control Mechanisms

Cost Optimization Strategies
| Strategy | Effort | Savings | Implementation |
|---|---|---|---|
| Prompt caching | Medium | 20-40% | OCI Functions + Redis |
| Model tiering | Low | 30-50% | Route simple queries to smaller models |
| Batch embedding | Low | 10-20% | Queue and batch embedding requests |
| Response caching | Medium | 15-30% | Cache common queries |
| Token optimization | High | 10-20% | Prompt engineering |
| Semantic caching | High | 20-40% | Cache similar queries |
Incident Response Framework
Incident Classification Matrix

Incident Response Runbooks

Common Incident Types
| Incident Type | Detection | Immediate Action | OCI Tools |
|---|---|---|---|
| Model timeout | APM latency spike | Switch to fallback model | Generative AI + Functions |
| Tool failure | Error rate increase | Circuit breaker + fallback | Functions + Logging |
| Quality degradation | Eval score drop | Roll back prompt | DevOps + Monitoring |
| Cost overrun | Budget alert | Rate limit + downgrade | Budgets + API Gateway |
| Prompt injection | Pattern detection | Block + investigate | Logging Analytics |
| Data breach | Audit anomaly | Isolate + investigate | Security Zones + Audit |
Automated Remediation

Security and Compliance
Security Control Framework

Data Classification and Handling
| Classification | Description | Allowed Models | Logging | OCI Controls |
|---|---|---|---|---|
| Public | Non-sensitive, shareable | All | Full | Standard |
| Internal | Business-sensitive | OCI-hosted only | Metadata | Private endpoints |
| Confidential | Customer data, PII | Dedicated cluster | Audit only | Customer keys |
| Restricted | Regulated data | Private Agent Factory | Audit only | Data residency |
Compliance Mapping
| Requirement | Control | OCI Implementation |
|---|---|---|
| GDPR Art. 17 | Data deletion | Object Storage lifecycle + DB purge |
| GDPR Art. 22 | Explainability | Trace logging + decision audit |
| SOC 2 CC6.1 | Access control | Identity Domains + Policies |
| HIPAA | PHI protection | Data Safe + Encryption + Audit |
| PCI DSS | Cardholder data | Tokenization + Isolation |
Team Operating Model
Roles and Responsibilities

On-Call Structure
| Rotation | Scope | Hours | Escalation |
|---|---|---|---|
| Primary | All P1/P2 incidents | 24/7 | ML Engineer or Platform Eng |
| Secondary | Escalation backup | 24/7 | AI Platform Lead |
| Specialist | Model-specific issues | Business hours | ML Engineer (on-call) |
Communication Channels
| Channel | Purpose | Response Time |
|---|---|---|
| #ai-platform-alerts | Automated alerts | Monitor during on-call |
| #ai-platform-support | Team support requests | 4 hours (business) |
| #ai-platform-incidents | Active incident coordination | Immediate |
| Weekly AI Ops Review | Metrics review, improvements | Weekly |
Production Readiness Checklist
Pre-Launch Checklist
| Category | Item | Required | Notes |
|---|---|---|---|
| Security | RBAC configured | Yes | Identity Domains |
| Security | Network isolation | Yes | VCN + Private endpoints |
| Security | Secrets management | Yes | OCI Vault |
| Security | Input validation | Yes | Functions + WAF |
| Reliability | Timeouts configured | Yes | All external calls |
| Reliability | Retries with backoff | Yes | Transient failures |
| Reliability | Fallback behavior | Yes | Graceful degradation |
| Reliability | Circuit breakers | Recommended | High-frequency tools |
| Quality | Golden set tests | Yes | 500+ cases |
| Quality | CI/CD integration | Yes | DevOps pipelines |
| Quality | Online evaluation | Recommended | Sampling |
| Cost | Budget alerts | Yes | OCI Budgets |
| Cost | Rate limiting | Yes | API Gateway |
| Cost | Cost attribution | Recommended | Tagging |
| Observability | Distributed tracing | Yes | APM + OpenTelemetry |
| Observability | SLOs defined | Yes | Monitoring |
| Observability | Alerting configured | Yes | Notifications |
| Governance | Prompt versioning | Yes | Git repository |
| Governance | Audit logging | Yes | Logging + Audit |
| Governance | Runbooks documented | Yes | At least 3 |
Launch Day Checklist
- All pre-launch items verified
- Staging environment tested
- Rollback procedure documented and tested
- On-call schedule confirmed
- Stakeholders notified
- Monitoring dashboards visible
- Canary deployment started (5%)
- Initial metrics baseline captured
Series Complete
This three-part series has provided a comprehensive framework for production AI systems on OCI:
- Part 1: Architecture — Six-plane enterprise architecture with OCI service mapping
- Part 2: Agent Patterns — Six orchestration patterns with decision frameworks
- Part 3: Operating Model — 5-stage maturity model, evaluation pipelines, incident response, and team structure
Next Steps
| Maturity Stage | Recommended Actions |
|---|---|
| Stage 1 | Start with Part 1 architecture patterns |
| Stage 2 | Implement basic monitoring and prompt versioning |
| Stage 3 | Build evaluation pipelines using this guide |
| Stage 4 | Implement A/B testing and automated quality gates |
| Stage 5 | Design autonomous operations architecture |
Resources
- OCI AI Agent Platform Documentation
- OCI APM for GenAI Observability
- OCI DevOps CI/CD
- OCI Budgets and Cost Management
- OpenTelemetry OCI Integration
- OCI AI Blueprints (GitHub)
Visit the AI CoE Hub for all resources, decision frameworks, and links to Oracle Architecture Center patterns.
Related Articles
- Part 1: Six-Plane Architecture — Foundation and design principles
- Part 2: Agent Patterns — Implementation patterns for production agents
- Observability Stack for Multi-Agent Systems — Monitoring and tracing at scale
Get Started
Build your first AI system
Step-by-step guide to setting up ACOS, creating your first agent, and shipping real products with AI.
Start buildingTemplates & Blueprints
Production-ready architecture
Download AI architecture templates, multi-agent blueprints, and prompt engineering patterns.
Browse templatesInner Circle
Join the builder community
Connect with creators and architects shipping AI products. Weekly office hours, shared resources, direct access.
Join the circleRelated Research
Read on FrankX.AI — AI Architecture, Music & Creator Intelligence
Stay in the intelligence loop
Weekly field notes on AI systems, production patterns, and builder strategy.
Continue Reading

Enterprise AI18 min read
Production LLMs & AI Agents on OCI: Part 1 - The Six-Plane Enterprise Architecture
The complete enterprise architecture blueprint for deploying production-grade LLM and agentic AI systems on Oracle Cloud Infrastructure. Six architectural planes, OCI service mapping, and the decision framework that gets you from demo to deployment.
Read article
Enterprise AI22 min read
Production LLMs & AI Agents on OCI: Part 2 - Six Agent Orchestration Patterns
The complete pattern library for agent orchestration on OCI: Sequential, Concurrent, Group Chat, Handoff, Orchestrator-Worker, and Human-in-the-Loop. Decision criteria, OCI service mapping, and when to use each pattern.
Read article
AI & Systems9 min read
Oracle GenAI Agents vs LangGraph vs CrewAI: Enterprise AI Agent Comparison 2026
A practical comparison of OCI GenAI Agents, LangGraph, and CrewAI for enterprise deployments. Features, pricing, and decision framework from an AI architect's perspective.
Read article